C语言实训-网页服务器
此项目仅作为教学实训作品上交,并不适用于正式项目上纲上线。因为项目中的搭建的 http 服务并不完善,不支持会话中持续的上下文传递。此外,对于报文的处理也比较简陋,解析器可能会存在内存泄漏的情况,具体查看 “已知问题” 部分。
介绍
| 实训内容 | 效果实现 |
|---|---|
 |
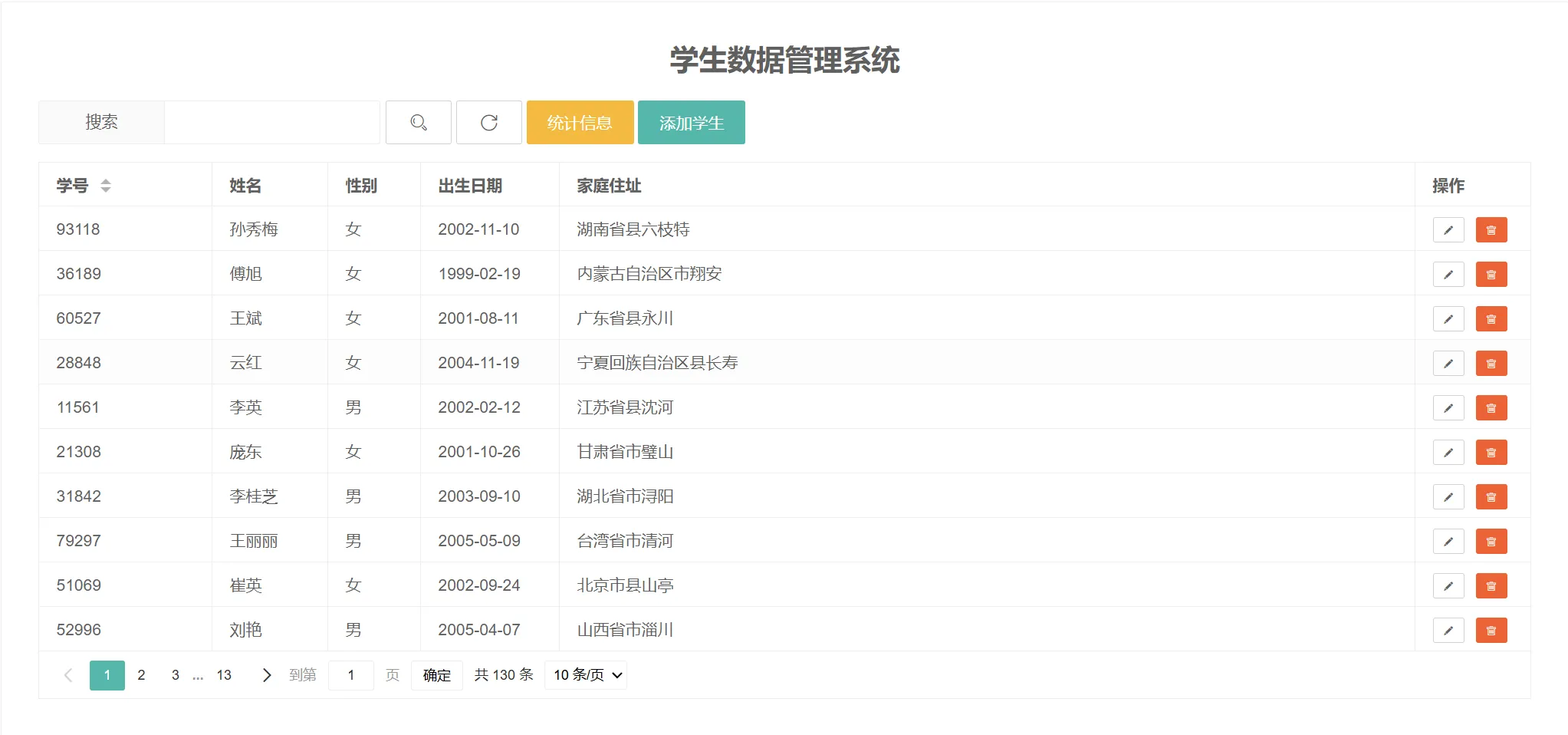 |
此项目是对学校C语言实训课选题一的实现与进阶,旨在学习C语言与挑战使用C语言写前后端。该项目实现了一个学生数据管理功能,包括学生数据的增删改查与数据统计。
该项目设计使用的技术栈如下:
- C语言(那是肯定的啦
- HTTP 报文的解析与生成 (后端)
- sqlite3 的数据库读写 (后端)
- Layui 框架(HTML、JavaScript、CSS) (前端)
此外,编写代码过程中使用到的主要工具有:
- CLion
- DB Browser (SQLite)
已知问题
- 可能存在内存泄漏问题,由于习惯了 Python 的自动回收机制,在 C 中可能会存在部分对象未及时释放,导致内存泄漏。
- 虽然代码中对部分实现功能不同的函数放在了不同源代码文件中,当仍然缺乏统一规范的注释以及优化。即使对于程序的实现是面向对象,但是仍有部分面向程序。
- 代码对 http 报文解析不完美,不支持解析 post 表单数据的解析,所以程序中均使用 get 方式传递数据。
- 为了减少工作量,默认的路由函数理论上支持所有请求方式,因为没有对请求方式进行进一步的判断与验证。
- 项目中的 include 文件夹和 lib 文件夹中尽可能包含了所有运行时需要的库文件,理论上这一步应当在 CMakeLits.txt 中标注所需要的库,但是原谅我,因为安装库这种东西实在太麻烦了,我可以不想在不同电脑中演式的时候出现缺少库的情况。
- 不稳定,不保证频繁请求下不会出什么问题(C语言太麻烦啦o(╥﹏╥)o
编译说明
推荐使用 CLion IDEA 环境进行编译生成,项目已经将所有的运行时DLL打包,理论上在任意电脑上编译没有问题。由于项目依赖于多个支持库,而编写代码均是在 CLion 上完成的,同时在 Visual Stduio 上可以正确编译该项目。
该项目至少依赖于下面的几个支持库:
- uv (用于 TCP 通信)
- glib (提供类列表、类字典的对象)
- json-c (用于 json 转化)
- libsqlite3 (用于读写 sqlite3 数据库)
项目使用 CMake 作为构建工具,推荐使用 MinGW 工具链,项目中的 include 文件夹中,除了 webhttpd 和 srclink 之外,均为提取的支持库部分源代码,这些代码配合 lib 中的动态链接库使用,基本可以在 MinGW 上构建并生成可执行程序。
通过我的不懈努力,现在可以使用 Visual Studio 和 CLion 构建了,而且 lib 中均为我已经编译好的静态库,不会产生任何多余的支持库文件,发布版本时,建议使用 Visual Stduio 进行构建, MinGW 构建出来的 JSON-C 依赖其他文件。
- 手动构建
首先确保拥有 cmake 的环境,然后再终端中输入如下内容生成构建文件:
cmake -G "CodeBlocks - MinGW Makefiles" -S . -B .\cmake-build-debug
进入并构建
cd cmake-build-debug cmake --build .
当然,你可以直接在 Release 中下载我编译好的程序。
编程说明
由于此项目运用了多个支持库,并且将每个支持库的库源文件和静态链接库均独立出来打包,所以在进行编程时理论上无需安装任何运行库。在 Windows 平台下,我将这些支持库在 MSVC 和 MinGW 的环境下静态编译,并在 MinGW 环境和 Visual Stduio 下测试通过。
使用 CLion 进行编程
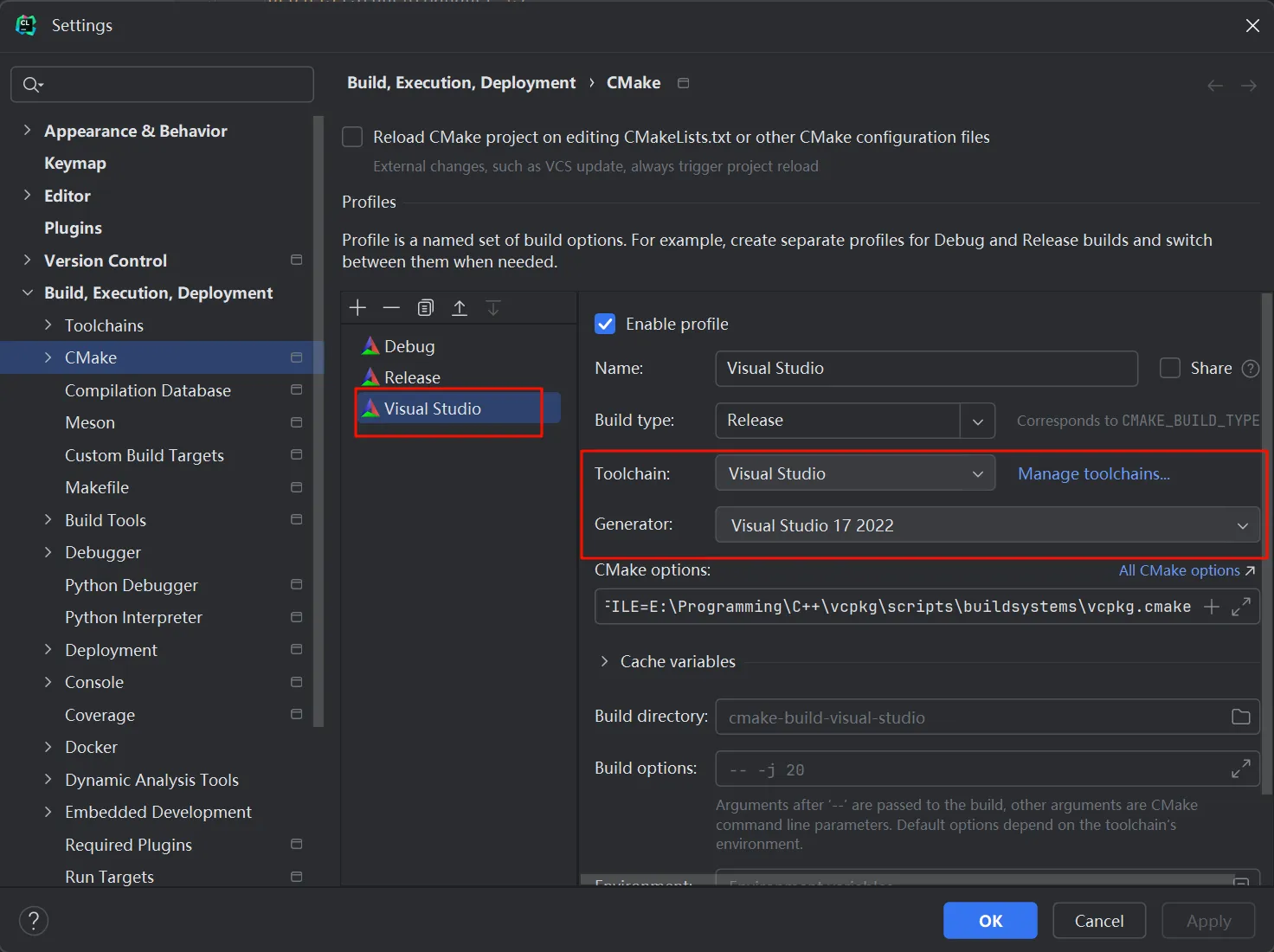
安装 CLion 之后(并配置好系统环境),克隆该项目,并在 CLion 中打开。理论上会进行自动配置,弹出下方的构建选项:

选择默认配置即可,而后可以在 CLion 页面进行编程。
使用 Visual Studio 进行编程
克隆该项目,打开该项目根目录,进入 Visual Studio ,依次打开:
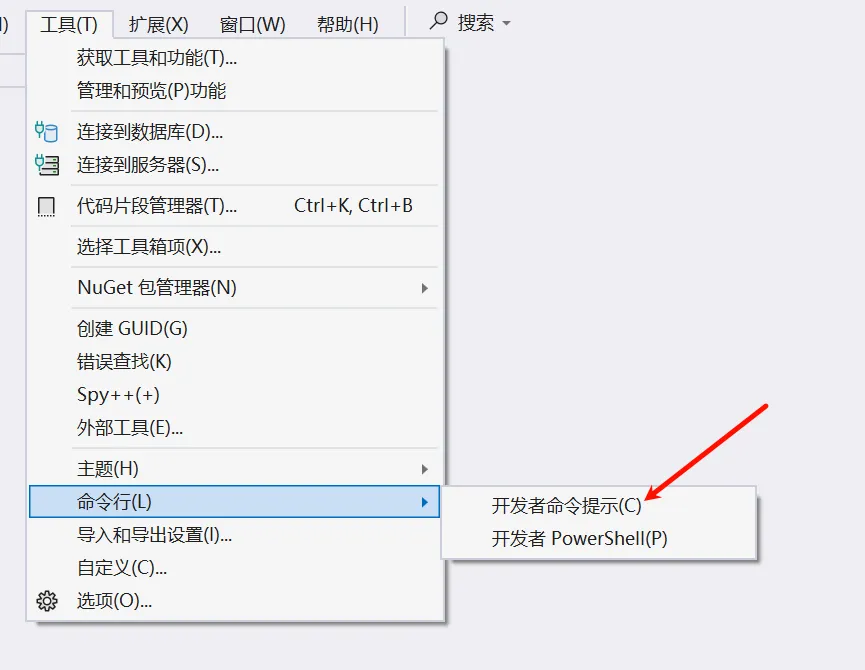
确保有 CMake 环境(没有去安装):
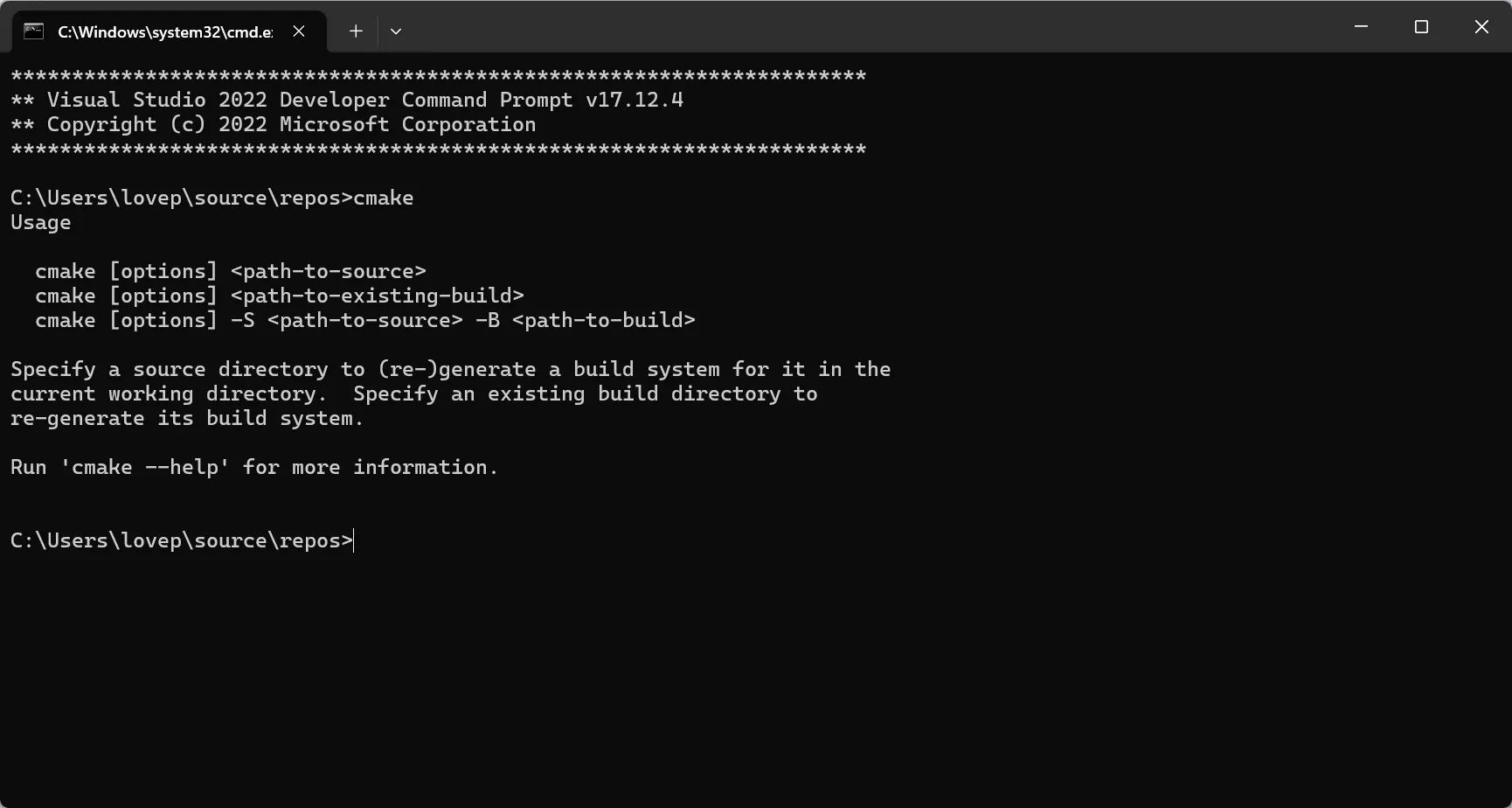
切换到项目根目录,输入:cmake -G "Visual Studio 17 2022" .(需要确认自己安装的版本)
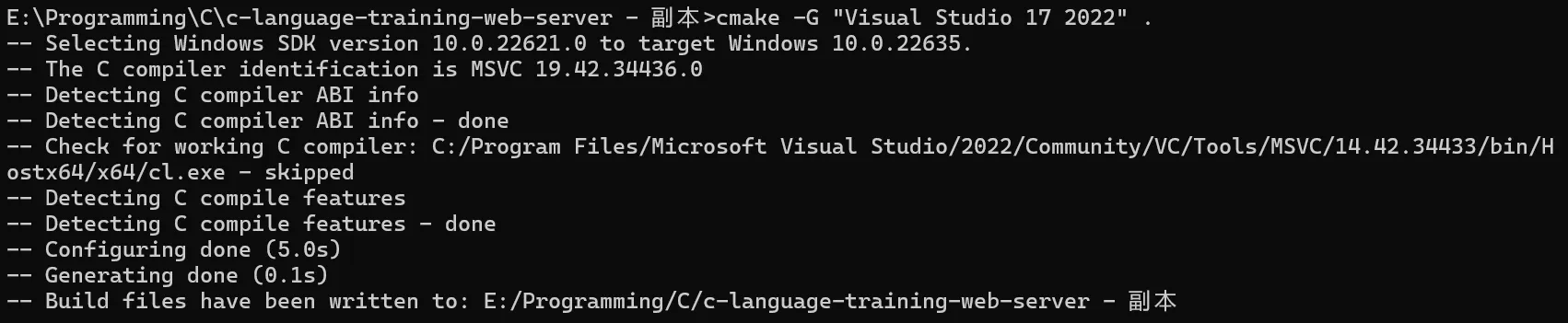
随后会生成 Visual Studio 的工程文件:
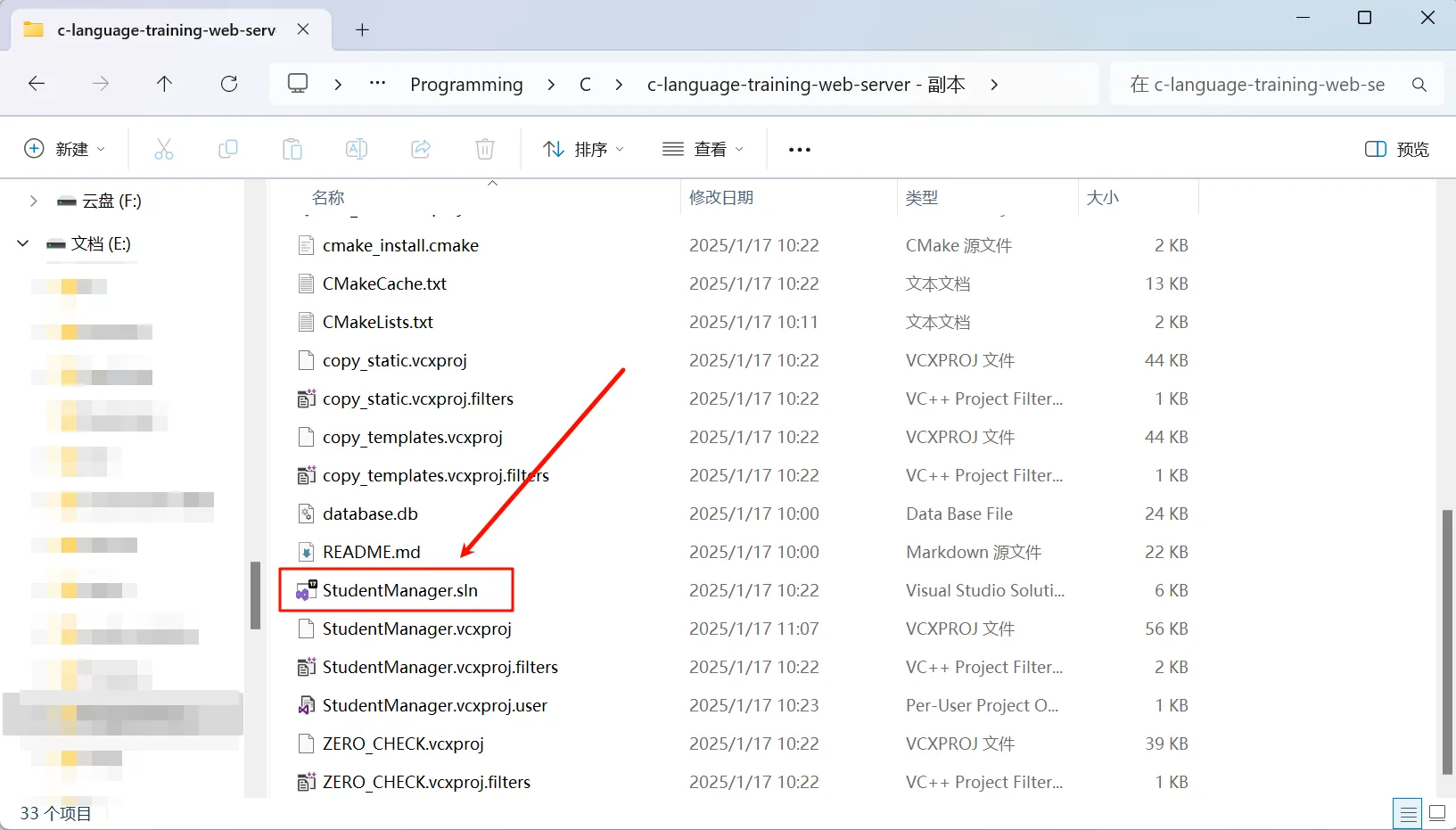
在 Visual Stduio 中,右侧解决方法,右键 “StudentManager” , 设为启动项目。
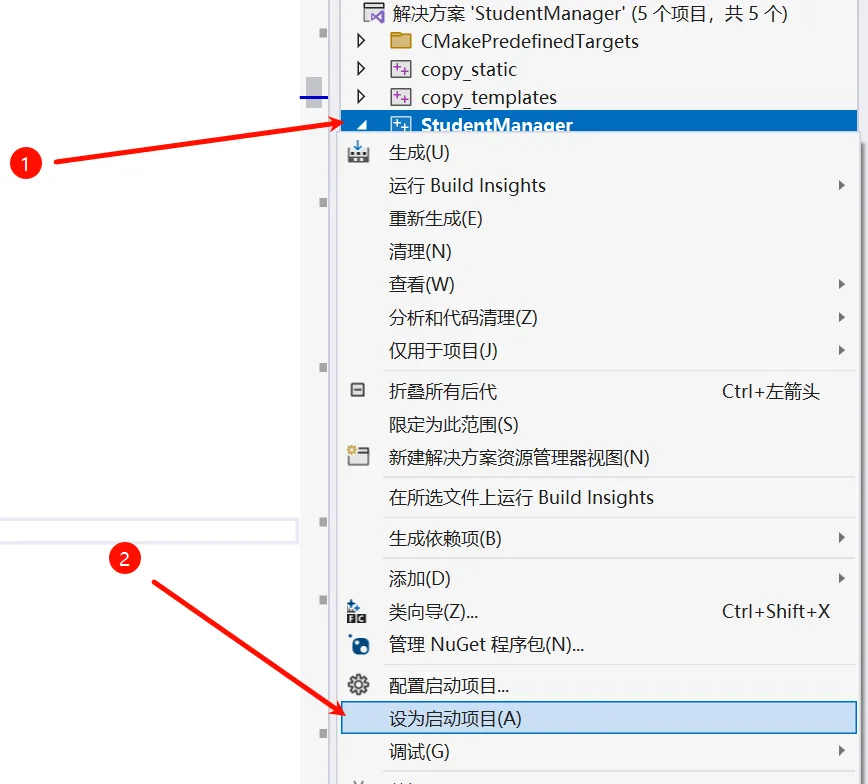
然后可以进行编程了。
| 需要保留的文件 | 配置 vcpkg |
|---|---|
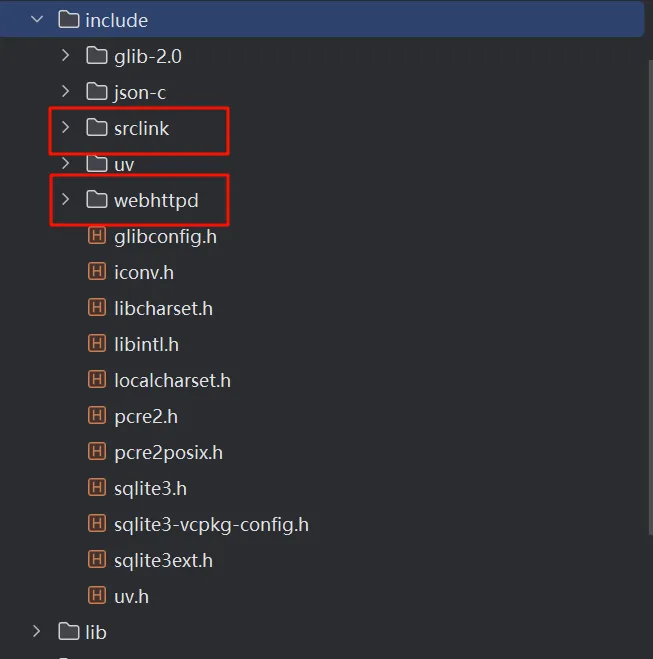 |
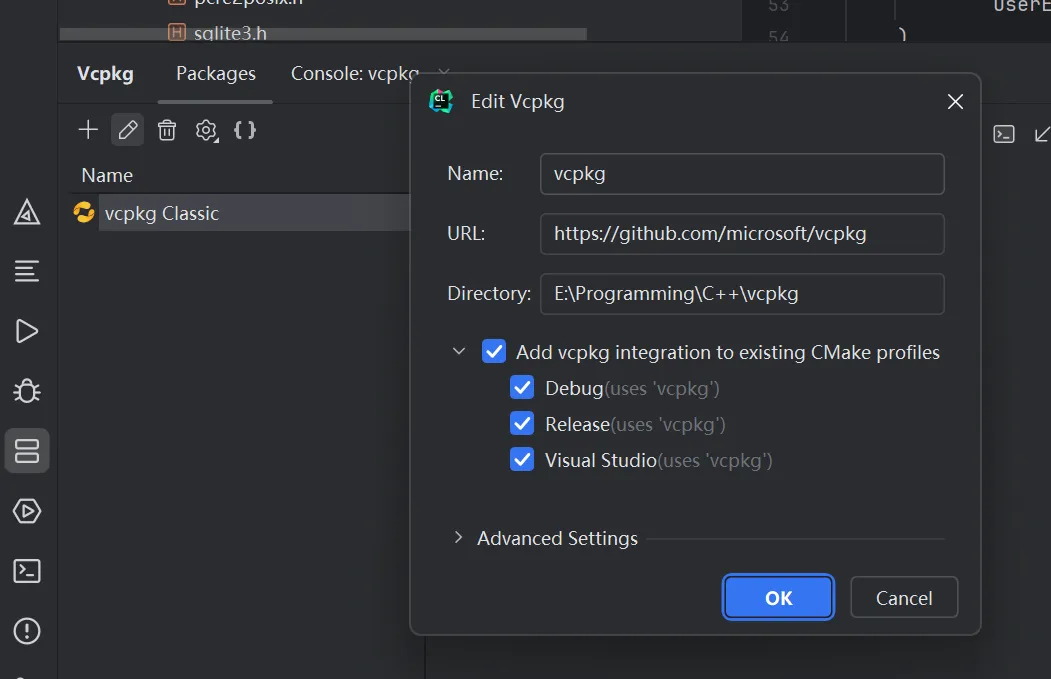 |
目录架构
本项目 ├─ CMakeLists.txt # CMakeLists 构建文件 ├─ database.db # 预设学生数据的 sqlite3 数据库 ├─ README.md # 说明文档 ├─ templates # 前端 HTML 页面存放文件夹 │ ├─ add.html # 添加学生 │ ├─ edit.html # 编辑学生 │ ├─ index.html # 主页 │ └─ stat.html # 数据分析(年龄统计) ├─ static # 静态前端资源 │ ├─ echarts.min.js # 图表 JS │ └─ layui # layui 界面库 ├─ src # 项目源文件 │ ├─ backend.c # 后端 │ ├─ frontend.c # 前端 │ ├─ main.c # 入口点 │ ├─ static_response.c # 静态资源响应(前端) │ └─ utils.c # 使用功能 ├─ lib-MSVC # MSVC 的静态库 ├─ lib # MinGW 的静态库 └─ include # 支持库文件 │ ├─ srclink # 与源文件链接的头文件 │ ├─ webhttpd # 自己写的头文件(实现 HTTP 服务器) │ │ ├─ Basic.h # 套接字、进行响应 │ │ ├─ HttpRequest.h # 请求解析 │ │ └─ HttpResponse.h # 响应生成 │ └─ ...... └─......
探索步骤
起因
下学期课多,我先把实训的作业完成(或者说先把框架搭好),是不是轻松一点?😄我熟悉前后端的开发,为什么我不把这个“管理系统”升级为前后端呢?这不正是实训课程中的“举一反三,加深理解,提高学生综合运用所学知识的能力”吗?
搭建 HTTP 服务器并以此区别每个路由的相应,可以参考 Flask 的处理方式,所以我们的设计的大体思路如下:
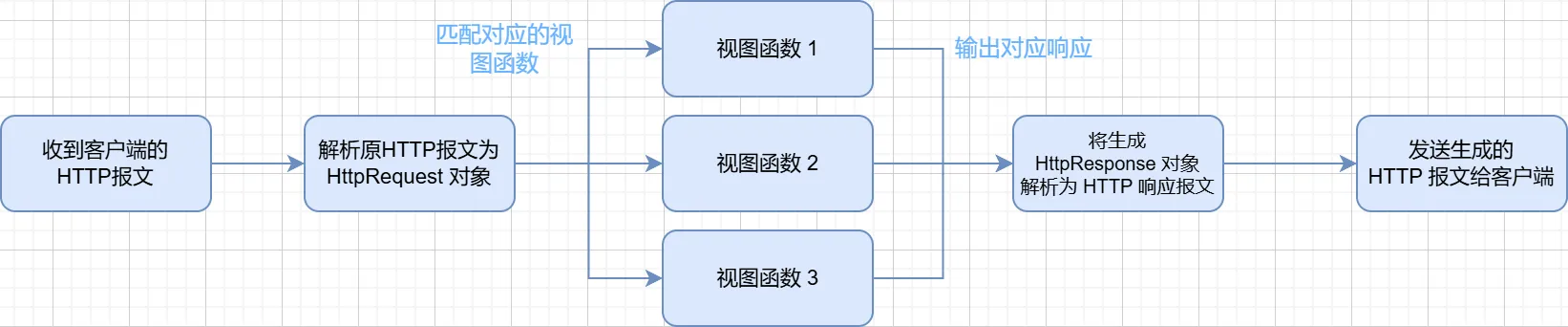
解析 HTTP 请求报文
说干就干,想要搭建网页服务器,我们要先理解网页服务器的基本原理。实际上,HTTP 协议是基于 TCP 协议的,HTTP 协议中规定了通讯的报文格式,从而可以正确传递网页的数据和内容。所以我们只需要让 TCP 服务器可以按照正确的方式响应浏览器发送过来的 HTTP 报文即可。(如下图)
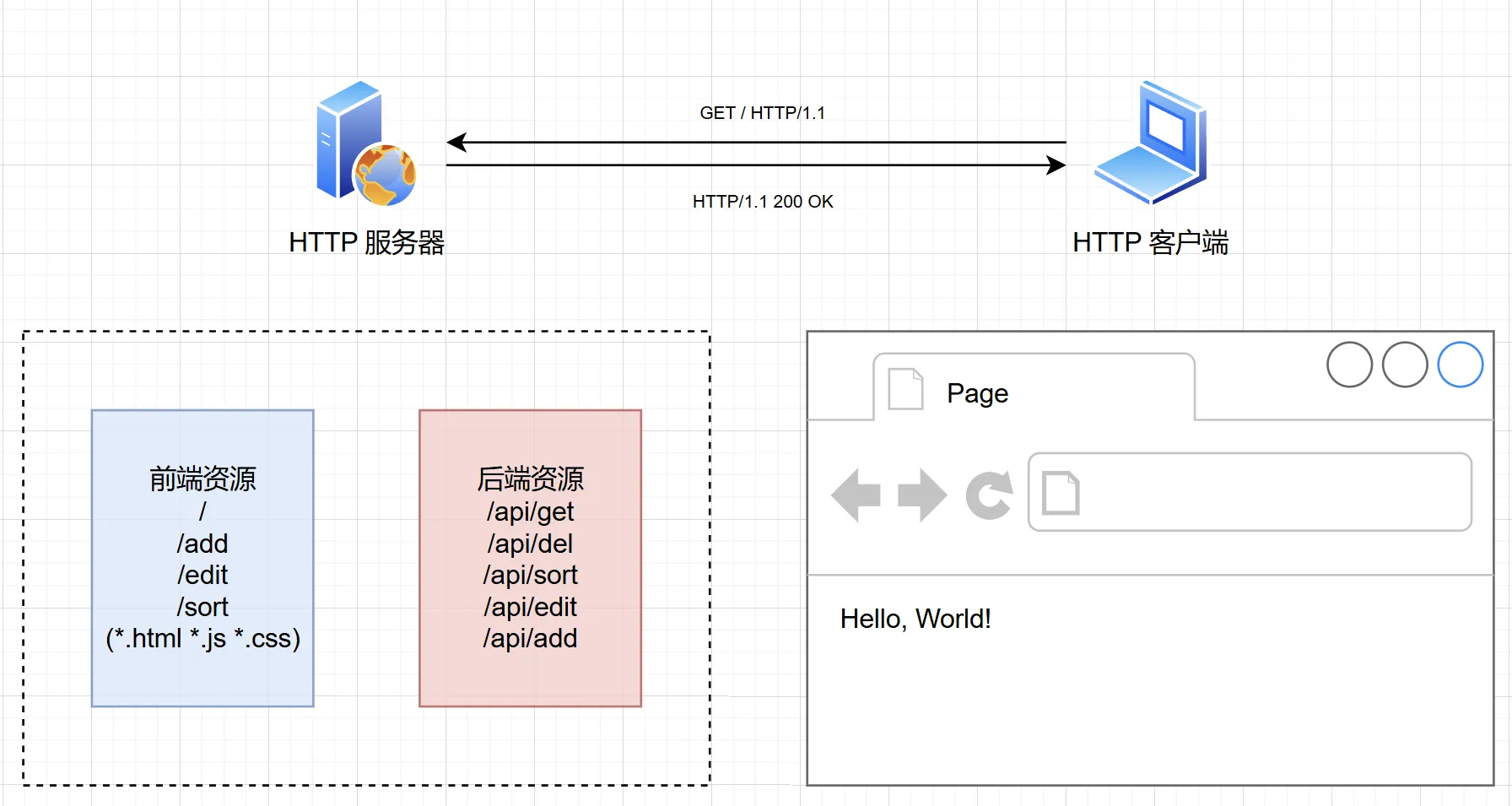
一个基本的 HTTP 请求和响应如下:
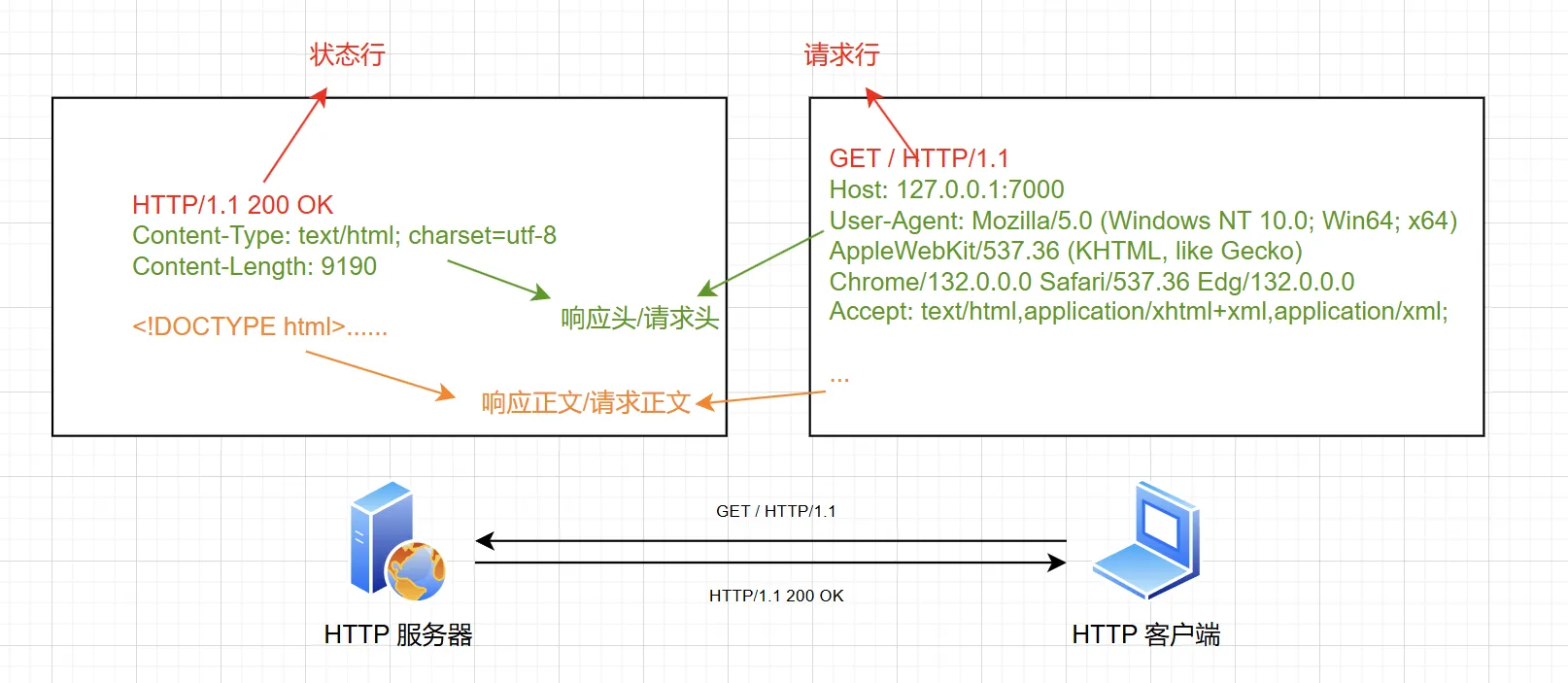
我们先从解析 HTTP 请求报文开始,HTTP 请求报文是一行一行的(除了正文内容),第一行是请求行,标明了 请求方式 、 请求地址 以及 请求协议 版本。紧接着每一行均为 请求头 ,直到最后空行结束,附带上 请求正文 (可以没有)。这里科普一下, 请求正文 一般是用来携带 POST 的表单数据 或者是 文件数据 的。
因为都是明文传输,所以解析起来也相对比较容易,难点在于如何使用 C 代码去解析,我的程序的设计逻辑大体是遵循 Python 的 Flask 进行设计的,我的设想是建立一个结构体,其中包含了这个请求的基本数据,例如:
typedef struct HttpRequestBody {
char *content;
size_t size;
} HttpRequestBody;
typedef struct HttpRequest {
GHashTable *headers;
char method[10];
char path[10240];
char protocol[20];
char remote_addr[INET_ADDRSTRLEN];
int remote_port;
HttpRequestBody body;
} HttpRequest;
在使用其他编程语言的时候,响应正文的类型都是 “字节型(bytes)” ,但是C语言中鲜有类似的对象出现,而是用 char * (字符串)来表示,原因是字节型本质上就是内存中的二进制,char类型虽然是字符,实际上是出于人们对其的解释为“字符”,对于非字符数据,char是可以保存的。另外,C语言中没有类似 len() 或者 length 之类的方法或者对象来获取字节长度,所以需要自行标明。此外 size_t 被宏定义为 unsigned long long 。
我将请求头放在哈希表中进行对应,这样可以方便的取出对应的值,对于正文内容,在另外设置一个结构体来存储其正文内容和长度。(虽然在我设计的程序中这些没有用到,因为根本没有用到 POST 来传递数据。)
此外,你会发现这里的 HttpRequest 缺少了 args 和 form 两个在 Python 中分别表示 GET 请求表单和 POST 请求表单对象的对象。这里是为了方便我并未设置,不然就要大费周章去做解析了。实际上,GET表单请求的内容会被 URL 编码而后放在 path 中(如下),因为程序会使用到 get 提交的表单数据,所以我专门设立了一个函数 parse_querys 用于解析地址中 “?” 之后的表单信息,该函数会返回一个对应的哈希表。(尚未测试重复键的行为会怎么样,可能会导致程序崩溃吧,笑)
/add?uid=114514&name=姓名...
解析的代码在 include/webhttpd/HttpRequest.h ,这里提供一下解析的流程图:
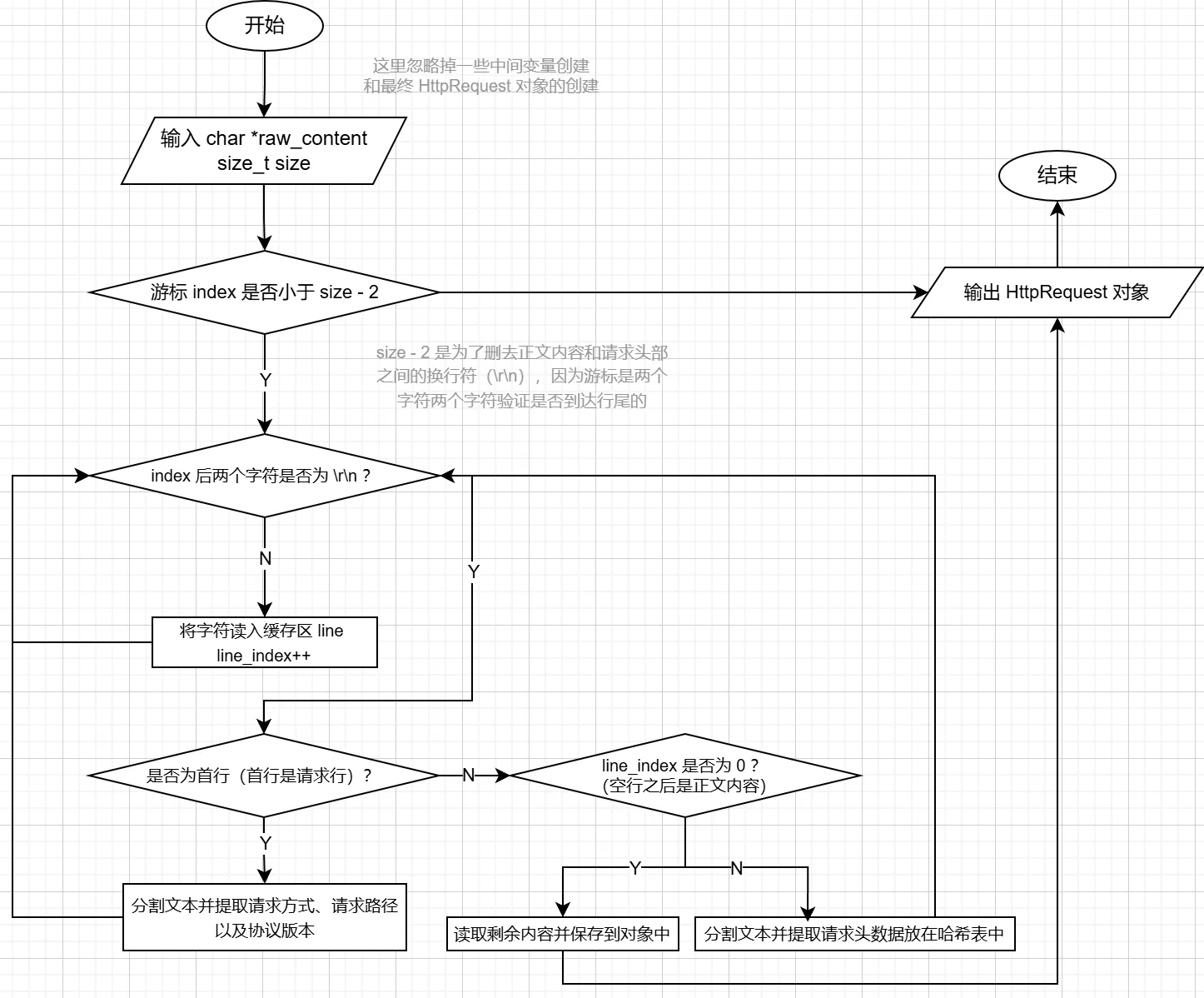
分割文本用到的 strtok 函数有点像易语言中的 分割文本 函数,以前思考不明白为什么易语言偏偏要使用这样“循环式”分割文本(为什么不像 Python 一样直接变成列表),现在明白原来是参考C语言的设计,这样分割文本避免了没有“列表”的问题(主要是如果用数组存,需要额外知道每个子串的长度来确定分配内存大小,不用数组)会更快一些。
将这个流程定义为函数 parse_request,而后在TCP服务器获取客户端数据的地方,将获取的数据传入该函数,并获得 HttpRequest 对象。
生成 HTTP 响应报文
解析之后就要生成响应了,同样生成响应至少需要一下内容: 响应协议版本 、 响应状态码 、 响应状态 、 响应正文长度 、 响应正文 。
typedef struct HttpResponseBody {
char *content;
size_t size;
} HttpResponseBody;
typedef struct HttpResponse {
int status_code;
GHashTable *headers;
HttpResponseBody body;
} HttpResponse;
typedef struct HttpResponseRaw {
char *content;
size_t size;
} HttpResponseRaw;
随后我们写一个函数用于将 HttpResponse 对象拼接成为响应报文,流程图就不画了,主要是进行字符串的拼接,这里说一下新认识的几个函数:
- int snprintf ( char * str, size_t size, const char * format, … ) 将指定的内容写入缓存区,参考 printf ,可以用于将输出的内容直接输出到 char * 字符串中。
- int sscanf(const char str, const char format, …) 这个函数实际上并没有在这里用到,主要为了和上面的函数匹配,这个用于从 char * 中按照指定格式提取内容。
匹配视图函数
接下来的事情就是匹配视图函数了,就是决定浏览器的请求需要被那个函数处理并生成响应。我们可以使用字符串匹配的方式来匹配请求的路由,简单的例子就是,假设浏览器请求 “/apple” 我们在程序中写一个 switch 语句,如果匹配到 “/apple” 就执行 apple_response() 函数。就是简单的一对一嘛。
不过问题在于,简单的字符串匹配会出问题,简单的例子就是,假设浏览器请求 /static/test.js ,但是偏偏带上了查询参数,例如 /static/test.js?v=1.0.2 ,来查询指定版本(这种方式主要是为了避免 cdn 缓存和热更新用的)。显而易见,如果加上查询参数,就不能简单使用字符串比较了,所以为了方便与简单,直接使用正则表达式匹配好了,这样灵活性更高。
设想如下:我们定义一个哈希表,并把正则匹配的字符串最为键,把视图函数的指针作为值,随后在TCP服务器响应客户端数据的地方变量哈希表,如果正则匹配则执行对应的视图函数。
static void add_route(char *route_pattern, HttpResponse (*handler)(HttpRequest)) {
g_hash_table_insert(RouteMap, g_strdup(route_pattern), (gpointer) handler);
}
处理浏览器请求
资源文件
经过上面的设计之后,我们只需要关注当个路由函数如何实现就行了。我们先来解决前端问题,即传输资源文件如 js、css、html 什么的。我们可以参考 Flask 设计方法,即将所有静态文件均放在文件夹 static 中,请求路由 /static/* 即可访问到 static 文件夹下的资源文件(定义一个 static_response 函数)。
传输资源文件需要注意的是其的 mime 类型,为了方便这里使用直接后缀名对应的方法。除此之外就是传输文件内容了,即用 fopen(FILE, "rb") 打开文件并读取传输。在读取之前还要先得知其文件大小,这个可以使用“移光标”的方法:
fseek(file, 0, SEEK_END); long file_size = ftell(file); fseek(file, 0, SEEK_SET);
html 网页
本质上 html 就是一个静态文件,但是如果放在 static 文件夹中并请求太不 city 了,主要是上述我们强制将资源文件全部设定在了 /static/ 路由下,如果不这样操作(资源文件直接挂在 / 下)的话还要另外判断,而且不太符合程序的目录架构(因为要遵守 Flask 嘛,笑)。所以,我创建了一个文件夹叫做 templates 专门用于存放 html 网页文件,接着定义一个函数 send_templates (类似于 Flask 的 render_template 就是没有变量传递的功能) 用于传递网页。本质上这个函数就是指定了路径的 static_response 函数。
HttpResponse send_template(HttpRequest request, char *filepath_) {
char filepath[BUFFER_SIZE] = "./templates/";
strcat_s(filepath, BUFFER_SIZE, filepath_);
FILE *file = fopen(filepath, "rb"); // 以二进制模式打开文件
if (!file) {
return not_found_response(request);
}
// 获取文件大小
fseek(file, 0, SEEK_END);
long file_size = ftell(file);
fseek(file, 0, SEEK_SET);
// 读取文件内容到缓冲区
char *file_content = malloc(file_size);
fread(file_content, 1, file_size, file);
fclose(file);
// 构造响应
HttpResponse response;
response.status_code = 200;
response.headers = g_hash_table_new_full(g_str_hash, g_str_equal, g_free, g_free);
// 设置 MIME 类型
const char *mime_type = get_mime_type(filepath);
g_hash_table_insert(response.headers, g_strdup("Content-Type"), g_strdup((char *) mime_type));
// 设置响应体内容和大小
response.body.content = file_content;
response.body.size = file_size;
return response;
}
所以,我们可以方便的指定前端页面的地址:
HttpResponse index_route(HttpRequest request) {
return send_template(request, "index.html");
}
HttpResponse add_student_route(HttpRequest request) {
return send_template(request, "add.html");
}
HttpResponse edit_student_route(HttpRequest request) {
return send_template(request, "edit.html");
}
HttpResponse stat_route(HttpRequest request) {
return send_template(request, "stat.html");
}
是不是很赏心悦目啊(
后端请求
后端路以 /api 开头,大体与上述类似,不过后端要大量用到 json 转化,所以使用了 json-c 来生成 json 数据。
构建前端页面
终于到我拿手的时候了,C语言写HTTP服务器简直就是折磨,但是写前端的html是一种享受,因为你不需要去讨论函数传递、指针传递的问题。
简单来说,前端就是 页面 + 执行脚本 ,我们采用 layui Web UI 组件库,这样可以大大减少我们的代码量以及写出更好看的页面,具体的说明文档查看 (Layui)[https://layui.dev/] 。 界面设计主要使用:
- table 动态表格
- 表单组件(按钮、输入框)
对于统计数据页面采用 echart 绘图。
构建后端页面
由于后端页面的设计思路基本相同,这里就挑几个比较有特点的说一下,对于学生数据的获取、排序均由 sqlite3 数据库执行而来的。
学生数据获取
一般来说,对于数据库数据的获取与修改经过以下几个步骤:

- 解析参数:使用
parse_querys函数,将查询参数解析为哈希表的键值对 - 生成数据库查询语句:sqlite3_prepare_v2 + 参数绑定(确保不会被 SQL 注入)
- 解析为GList:
stmt_to_dict_list函数 - 转化为JSON:
g_list_to_json_array函数
注意:这里大部分的辅助函数并非是我写的,而是直接由GPT生成的,我并不想把时间浪费在写这个东西上面。
HttpResponse api_get_route(HttpRequest request) {
int page = 1, limit = 5;
// 解析 url 参数
GHashTable *dict = parse_querys(request.path);
if (dict) {
char *value = (char *) g_hash_table_lookup(dict, "page");
if (value) {
char *endptr;
int num = (int) strtol(value, &endptr, 10);
if (*endptr == 'HttpResponse api_get_route(HttpRequest request) {
int page = 1, limit = 5;
// 解析 url 参数
GHashTable *dict = parse_querys(request.path);
if (dict) {
char *value = (char *) g_hash_table_lookup(dict, "page");
if (value) {
char *endptr;
int num = (int) strtol(value, &endptr, 10);
if (*endptr == '\0' && num > 0) {
// 检查合法性
page = num;
}
}
value = (char *) g_hash_table_lookup(dict, "limit");
if (value) {
char *endptr;
int num = (int) strtol(value, &endptr, 10);
if (*endptr == '\0' && num > 0) {
// 检查合法性
limit = num;
}
}
g_hash_table_destroy(dict);
}
// 这里开始生成响应数据了
HttpResponse response;
response.status_code = 200;
response.headers = g_hash_table_new_full(g_str_hash, g_str_equal, g_free, g_free);
g_hash_table_insert(response.headers, g_strdup("Content-Type"), g_strdup("application/json; charset=utf-8"));
// 打开数据库连接
sqlite3 *db;
int rc = sqlite3_open(DATEBASE_NAME, &db);
if (rc != SQLITE_OK) {
return error_server_response(request);
}
// 获取表中全部数量
const char *count_query = "SELECT COUNT(*) FROM students;";
sqlite3_stmt *count_stmt;
rc = sqlite3_prepare_v2(db, count_query, -1, &count_stmt, NULL);
if (rc != SQLITE_OK) {
sqlite3_close(db);
return error_server_response(request);
}
int total_count = 0;
if (sqlite3_step(count_stmt) == SQLITE_ROW) {
total_count = sqlite3_column_int(count_stmt, 0);
}
sqlite3_finalize(count_stmt);
// 构建分页查询 SQL
const char *sql_template = "SELECT * FROM students LIMIT ? OFFSET ?;";
sqlite3_stmt *stmt;
rc = sqlite3_prepare_v2(db, sql_template, -1, &stmt, NULL);
if (rc != SQLITE_OK) {
sqlite3_close(db);
return error_server_response(request);
}
// 设置分页参数
sqlite3_bind_int(stmt, 1, limit); // 第 1 个参数是 LIMIT
sqlite3_bind_int(stmt, 2, (page - 1) * limit); // 第 2 个参数是 OFFSET
// 查询数据并转为 GList
GList *result_list = stmt_to_dict_list(stmt);
sqlite3_finalize(stmt);
sqlite3_close(db);
json_object *data_array = g_list_to_json_array(result_list);
const char *json_string = json_object_to_json_string_ext(
data_api_json(0, "success", total_count, data_array),
JSON_C_TO_STRING_PRETTY);
// 设置响应体
response.body.content = malloc(strlen(json_string) + 1);
response.body.size = strlen(json_string);
strcpy(response.body.content, json_string);
// 释放资源
free_dict_list(result_list);
return response;
}' && num > 0) {
// 检查合法性
page = num;
}
}
value = (char *) g_hash_table_lookup(dict, "limit");
if (value) {
char *endptr;
int num = (int) strtol(value, &endptr, 10);
if (*endptr == 'HttpResponse api_get_route(HttpRequest request) {
int page = 1, limit = 5;
// 解析 url 参数
GHashTable *dict = parse_querys(request.path);
if (dict) {
char *value = (char *) g_hash_table_lookup(dict, "page");
if (value) {
char *endptr;
int num = (int) strtol(value, &endptr, 10);
if (*endptr == '\0' && num > 0) {
// 检查合法性
page = num;
}
}
value = (char *) g_hash_table_lookup(dict, "limit");
if (value) {
char *endptr;
int num = (int) strtol(value, &endptr, 10);
if (*endptr == '\0' && num > 0) {
// 检查合法性
limit = num;
}
}
g_hash_table_destroy(dict);
}
// 这里开始生成响应数据了
HttpResponse response;
response.status_code = 200;
response.headers = g_hash_table_new_full(g_str_hash, g_str_equal, g_free, g_free);
g_hash_table_insert(response.headers, g_strdup("Content-Type"), g_strdup("application/json; charset=utf-8"));
// 打开数据库连接
sqlite3 *db;
int rc = sqlite3_open(DATEBASE_NAME, &db);
if (rc != SQLITE_OK) {
return error_server_response(request);
}
// 获取表中全部数量
const char *count_query = "SELECT COUNT(*) FROM students;";
sqlite3_stmt *count_stmt;
rc = sqlite3_prepare_v2(db, count_query, -1, &count_stmt, NULL);
if (rc != SQLITE_OK) {
sqlite3_close(db);
return error_server_response(request);
}
int total_count = 0;
if (sqlite3_step(count_stmt) == SQLITE_ROW) {
total_count = sqlite3_column_int(count_stmt, 0);
}
sqlite3_finalize(count_stmt);
// 构建分页查询 SQL
const char *sql_template = "SELECT * FROM students LIMIT ? OFFSET ?;";
sqlite3_stmt *stmt;
rc = sqlite3_prepare_v2(db, sql_template, -1, &stmt, NULL);
if (rc != SQLITE_OK) {
sqlite3_close(db);
return error_server_response(request);
}
// 设置分页参数
sqlite3_bind_int(stmt, 1, limit); // 第 1 个参数是 LIMIT
sqlite3_bind_int(stmt, 2, (page - 1) * limit); // 第 2 个参数是 OFFSET
// 查询数据并转为 GList
GList *result_list = stmt_to_dict_list(stmt);
sqlite3_finalize(stmt);
sqlite3_close(db);
json_object *data_array = g_list_to_json_array(result_list);
const char *json_string = json_object_to_json_string_ext(
data_api_json(0, "success", total_count, data_array),
JSON_C_TO_STRING_PRETTY);
// 设置响应体
response.body.content = malloc(strlen(json_string) + 1);
response.body.size = strlen(json_string);
strcpy(response.body.content, json_string);
// 释放资源
free_dict_list(result_list);
return response;
}' && num > 0) {
// 检查合法性
limit = num;
}
}
g_hash_table_destroy(dict);
}
// 这里开始生成响应数据了
HttpResponse response;
response.status_code = 200;
response.headers = g_hash_table_new_full(g_str_hash, g_str_equal, g_free, g_free);
g_hash_table_insert(response.headers, g_strdup("Content-Type"), g_strdup("application/json; charset=utf-8"));
// 打开数据库连接
sqlite3 *db;
int rc = sqlite3_open(DATEBASE_NAME, &db);
if (rc != SQLITE_OK) {
return error_server_response(request);
}
// 获取表中全部数量
const char *count_query = "SELECT COUNT(*) FROM students;";
sqlite3_stmt *count_stmt;
rc = sqlite3_prepare_v2(db, count_query, -1, &count_stmt, NULL);
if (rc != SQLITE_OK) {
sqlite3_close(db);
return error_server_response(request);
}
int total_count = 0;
if (sqlite3_step(count_stmt) == SQLITE_ROW) {
total_count = sqlite3_column_int(count_stmt, 0);
}
sqlite3_finalize(count_stmt);
// 构建分页查询 SQL
const char *sql_template = "SELECT * FROM students LIMIT ? OFFSET ?;";
sqlite3_stmt *stmt;
rc = sqlite3_prepare_v2(db, sql_template, -1, &stmt, NULL);
if (rc != SQLITE_OK) {
sqlite3_close(db);
return error_server_response(request);
}
// 设置分页参数
sqlite3_bind_int(stmt, 1, limit); // 第 1 个参数是 LIMIT
sqlite3_bind_int(stmt, 2, (page - 1) * limit); // 第 2 个参数是 OFFSET
// 查询数据并转为 GList
GList *result_list = stmt_to_dict_list(stmt);
sqlite3_finalize(stmt);
sqlite3_close(db);
json_object *data_array = g_list_to_json_array(result_list);
const char *json_string = json_object_to_json_string_ext(
data_api_json(0, "success", total_count, data_array),
JSON_C_TO_STRING_PRETTY);
// 设置响应体
response.body.content = malloc(strlen(json_string) + 1);
response.body.size = strlen(json_string);
strcpy(response.body.content, json_string);
// 释放资源
free_dict_list(result_list);
return response;
}
学生数据统计
实训大纲中要求统计学生的年龄数据,所以这里借助逐行读取数行并添加数据。
HttpResponse api_stat_route(HttpRequest request) {
// 打开数据库连接
sqlite3 *db;
int rc = sqlite3_open(DATEBASE_NAME, &db);
if (rc != SQLITE_OK) {
return normal_response(500, -1, "服务器错误");
}
// 构建查询 SQL
const char *sql_query = "SELECT birth FROM students;";
sqlite3_stmt *stmt;
rc = sqlite3_prepare_v2(db, sql_query, -1, &stmt, NULL);
if (rc != SQLITE_OK) {
sqlite3_close(db);
return normal_response(500, -1, "查询准备失败");
}
char tags[4][15] = {"17岁", "18岁", "19岁", "19岁以上"};
int counts[4] = {0, 0, 0, 0};
// 今年日期
time_t t = time(NULL);
struct tm *tm_info = localtime(&t);
int now_year = tm_info->tm_year + 1900;
while (sqlite3_step(stmt) == SQLITE_ROW) {
const char *birth = (const char *) sqlite3_column_text(stmt, 0);
int year, month, day;
sscanf(birth, "%4d-%d-%d", &year, &month, &day);
if (now_year - year == 17) {
counts[0]++;
} else if (now_year - year == 18) {
counts[1]++;
} else if (now_year - year == 19) {
counts[2]++;
} else if (now_year - year > 19) {
counts[3]++;
}
}
sqlite3_finalize(stmt);
sqlite3_close(db);
// 创建 JSON 对象
struct json_object *json_obj = json_object_new_object();
// 创建 JSON 数组并填充 tags
struct json_object *tags_array = json_object_new_array();
for (int i = 0; i < 4; i++) {
json_object_array_add(tags_array, json_object_new_string(tags[i]));
}
// 创建 JSON 数组并填充 counts
struct json_object *counts_array = json_object_new_array();
for (int i = 0; i < 4; i++) {
json_object_array_add(counts_array, json_object_new_int(counts[i]));
}
// 将 tags 和 counts 添加到 JSON 对象中
json_object_object_add(json_obj, "tags", tags_array);
json_object_object_add(json_obj, "counts", counts_array);
const char *json_string = json_object_to_json_string_ext(
data_api_json(0, "success", 0, json_obj),
JSON_C_TO_STRING_PRETTY);
HttpResponse response;
response.status_code = 200;
response.headers = g_hash_table_new_full(g_str_hash, g_str_equal, g_free, g_free);
g_hash_table_insert(response.headers, g_strdup("Content-Type"), g_strdup("application/json; charset=utf-8"));
// 设置响应体
response.body.content = malloc(strlen(json_string) + 1);
response.body.size = strlen(json_string);
strcpy(response.body.content, json_string);
return response;
}
打包说明

将项目进行构建之后,除了上述选择的文件之外,其余均可删除,你会发现这个可执行文件没有生成额外 dll ,这就是静态库静态链接的能力!但是如果使用 MinGW 打包,可能在一些电脑上无法正常运行,所以这里建议使用 Visual Studio (MSVC)环境生成最终的项目。